
Decisions and Evaluation
An introduction to their axiomatic relationship

There is a storytelling technique that is sometimes called the Matryoshka structure, named for the Russian nesting dolls. It goes like this: you start the story with a small problem that your character has, but you don’t solve it right away. In the pursuit of solving the first problem, the character stumbles on a bigger problem, which motivates a larger story arc. You also don’t solve this problem right away, but instead introduce the character to an even bigger problem which they discover in the process of solving the last one. You wrap up your story by going in reverse, solving the biggest problem first, then the second biggest, then in the last scene, once the listener has forgotten all about the original little problem, you come in and button the last button.
The story I’m about to tell about evaluation goes a bit like that, because it turns out that this structure also describes the relationship between classical decision theory and evaluation. We start with a small, real-world problem: someone in an organization wants to make at least one decision. A common kind of decision is the “go/no-go” decision for funding a program or policy, that is, will the organization keep funding the initiative? Another common kind of decision is among some alternative possibilities, like expanding the program, cutting the budget somewhat, altering the plan to serve only a subset of the original population, and other operational changes. These types of dilemmas are well described by classical decision theory. We have a choice, which leads to different outcomes.

We can complicate the picture a little bit by saying that the world may change in ways that later reveal our choice to have been good or bad.
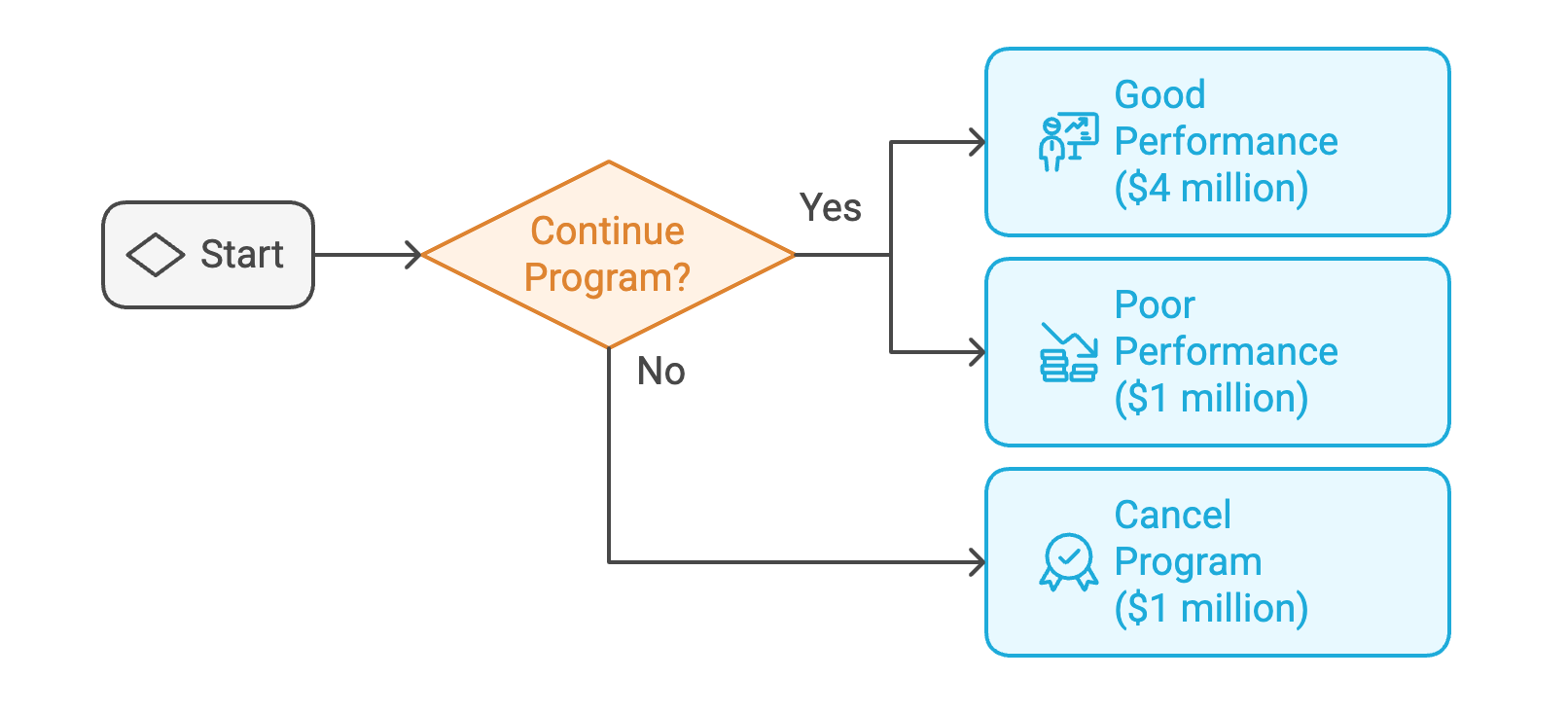
Of course, there are are also probabilities attached to these new chance outcomes. If we know the probability of Good Performance and Poor Performance, then we are making a decision “under risk”, while if we don’t know, then we are making a decision “under uncertainty.” In the example above, suppose that there is a 50/50 chance of having a good year if we continue the program. In that case, the expected value of continuing the program is the weighted value of each of the outcomes, in this case E(V) = .5(4 million) + .5(1 million) = $3 million.
This is the biggest nesting doll. We are trying to make a decision about a program or policy. Theoretically, any decision can be drawn out like this. All we need to know are the alternatives available, what these alternatives are conditional upon, and at least the ordering of our preferences. In my example above, we know the value in dollars of each outcome (more on this in a moment) but in decision theory we actually don’t need to get this specific. We just need to be able to put the utility of each outcome on an ordinal scale in relation to all the other outcomes: you don’t have to tell me exactly how much more you like chocolate than vanilla (cardinal utility), but you do have to be able to tell me that you like it more (ordinal utility). In decision theory, this is called the Completeness Axiom, and it asserts that for any two alternatives A and B, you must be able to express a preference between them or be indifferent such that:
A is preferred to B (A≻B),
B is preferred to A(B≻A), or
A and B are equally preferred (A∼B)
This axiom ensures that preferences can be ranked in an ordinal manner, allowing alternatives to be compared, even without specifying cardinal utilities. Without this axiom, the framework of decision theory cannot function coherently, since preferences would be undefined for some pairs of alternatives. This just makes sense: without the ability to order preferences, we cannot make rational decisions.
Should you take the new job offer or keep the old job? This depends on which one you prefer.
Should we increase the hospital equipment budget at the expense of hospital salary budget? This depends on the utility of each expenditure.
So now the big question: how do we determine the ordering of our preferences? How do we know that Good Performance is worth $4 million and Poor Performance is worth $1 million? The answer is evaluation. My argument is that this is axiomatically true for every single decision-theoretic problem, whether we do evaluation systematically or not.
Contained within every rational decision is an evaluation. This is the second Matryoshka doll.

When I tell people that evaluation is the process of determining the merit or worth of things, I find that I get one of two extreme responses: either they can easily imagine how this might be done or it sounds impossible to them. The truth is that evaluation is one of those hard-but-not-impossible tasks that also happens to be unavoidable in life. There are many processes for arriving at a cardinal or ordinal utility for an evaluand, even when the output is in monetary terms. For example, in cost-inclusive evaluation, we can estimate the cardinal utility of a program by measuring its benefits to the recipients, looking at the market prices of the goods it provides, or using contingent valuation techniques. There are many choices to be made, and they yield different valuations. A good analyst will show you the effects of different assumptions on the analysis. This is just within one kind of evaluation. To get the preference orderings we need, we might user goal-free evaluation or realist evaluation instead.
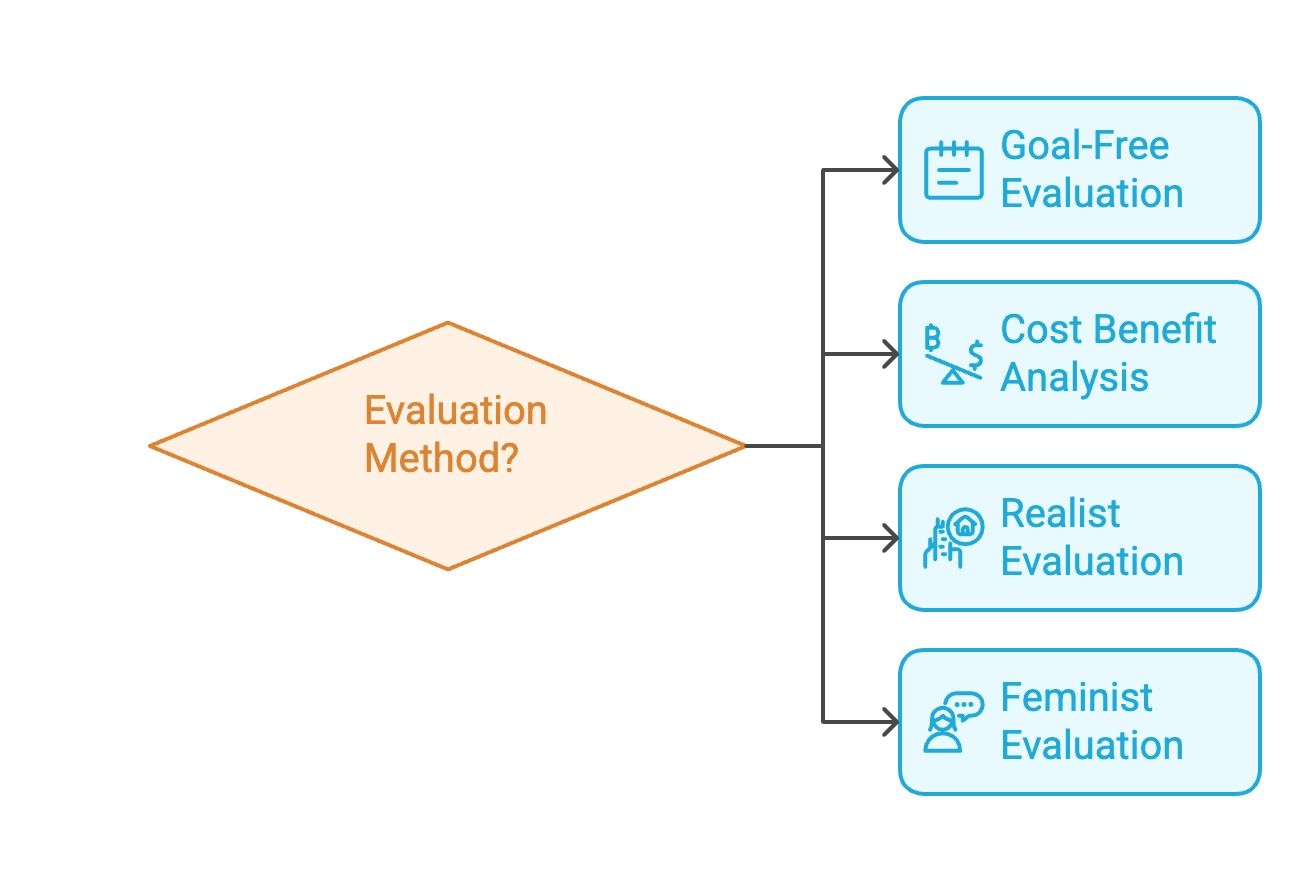
In each real evaluation situation, there are factors that make some evaluation approaches preferable to others. In other words, there is a decision to make among evaluation approaches. We need to make this decision in order to arrive at preference orderings for our first major question. Here’s the situation now:
Decision → Evaluation → Decision
This is the third Matryoshka doll, the decision between alternative evaluation approaches.
At this point, I’m sure you can guess where this is going. In order to make the decision between different evaluation approaches, the Completeness Axiom says we need to have preference orderings. There is nothing that says these preference ordering have to be universal or last forever – in fact, they can be entirely situational. They do, however, need to exist in order for us to make a rational decision. So, the next logical question emerges: how do we establish the preference orderings for different evaluation approaches? This will be the fourth Matryoshka.
We are going to need an evaluation of the various possible evaluation approaches in order to establish this preference ordering. How do we evaluate evaluation approaches? I think the answer comes down to the criteria we use to judge any theories. Some of these values might include explanatory power, generalizability, translatability into common metrics (e.g., money), and ethical alignment. Weighting different theoretical criteria differently, perhaps in different circumstances, yields different preference orderings for different evaluation methods. Whereas in the previous decision levels, we were choosing between categorically different options, now we are likely going to be choosing between different weighted combinations of criteria. We might be deciding between:
Weighting Scheme A: 25% explanatory power, 25% generalizability, 25% translatability into common metrics (e.g., money), and 25% ethical alignment
Weighting Scheme B: 10% explanatory power, 10% generalizability, 10% translatability into common metrics (e.g., money), and 70% ethical alignment
Weighting Scheme C: 5% explanatory power, 5% generalizability, 80% translatability into common metrics (e.g., money), and 10% ethical alignment

There is a jump in complexity here. The name for this kind of decision theory is Multi-Criteria Decision Analysis (MCDA). MCDA incorporates multiple criteria into the evaluation of options. Utility is modeled as a weighted sum (or another reasonable aggregation function) of the utilities associated with different criteria. Changing the weights of our utility function directly changes the judgments. In my simple example, I’m just using a weighted sum to judge different evaluation theories.
Let’s open all the dolls starting from here. If you decide to go with Weighting Scheme C, you will put lots of weight on translatability into common metrics, e.g., money. Formally, you are choosing this utility function to guide your choice of an evaluation method:
Thus, the optimal choice of evaluation methods will be a cost-inclusive evaluation method like cost-benefit analysis. Once you have chosen CBA, you now have an evaluation method to arrive at preference orderings for your major decision at the beginning. You went:
Major Decision →
Evaluation to Get Preference Orderings of Major Decision Alternatives →
Decision about Evaluation Method →
Evaluation to Get Preference Orderings of Evaluation Method Alternatives →
Decision about Weighting Schemes for Theoretical Values
Patterns
There are a few patterns that I think we should notice in this decision analysis. First, there is the obvious dialectic between decision and evaluation. Every decision ends up requiring an evaluation to set its preference orderings, and every evaluation requires a decision about how to conduct that evaluation. This dialectical movement is not circular but progressive – we aren’t returning to the same place over and over again, we are visiting new places and discovering that we need to do analogous work every time we arrive.

Second, it turns out that there are many temptations for us to stop evaluating and create arbitrary preference orderings. Even as I worked on this essay, I had to push myself through these barriers. It is easy to say that I “simply prefer” goal free evaluation because it “tends to work better” or has “overall advantages.” However, it is trivial to imagine certain contexts in which our preferences for certain evaluation approaches or weighted combinations of theoretical values could change. The universe does not hand out brownie points for consistent behavior. The temptation to stop explicitly reasoning about the criteria for our decisions gets worse as the dolls get smaller. If you can resist the temptation after level 5, then I think you are philosophically brave.
The third pattern to observe here is that evaluation criteria turn out to fit nicely into decision theory. You may be used to thinking of criteria as belonging to evaluation and utility as belonging to decision making, but:
Criteria (and standards) establish preference orderings among evaluands
Ordinal utility can always be derived from preference orderings
Thus, criteria are coefficients in a utility function
Now, the actual specification of that function is not a simple task. This is why Michael Scriven was always tossing out remarks like “Analysis of the usual way of integrating performance data by using numerical weights shows it to be fallacious” (Evaluation Thesaurus, 1991, p.6). Evaluators who use rubrics have pointed out that we need to watch out for simplistic additive weight-and-sum scoring procedures because they are implicitly compensatory, that is, they allow the evaluand to make up points in one dimension even if they fail completely in another dimension. In personnel evaluation, a compensatory rubric can mean that we give a score of 80% to a lunch-pail employee that gets the job done without a fuss and a very talented person who regularly pushes projects way over budget. “Regularly pushes projects way over budget” should be a disqualifying characteristic. This alternative to compensatory rubrics is known as the multiple-cutoff approach. Using the multiple-cutoff approach, we would automatically assign a failing score the personnel who misses the minimum on a key dimension. All we have to do is change the utility function to be multiplicative instead of additive, i.e., for the utility function to choose an evaluation method above:
Now, if any criterion has a score of 0, the entire utility goes to 0, changing the logic from compensatory to multiple-cutoff. All this is to say that criteria easily become part of utility functions, even then scoring rules start to get more complicated. If they get very complicated, we can always create a decision tree to yield the utility function for a preference ordering in another decision tree. This is called meta-decision analysis.
Practical Implications
Now that understand how evaluation and classical decision theory are related, you can try the following:
Create an explicit model of your decision to pursue a particular evaluation method with stakeholders before you commit to the method. Use the model to figure out what information would be required to make a good decision.
Do a retrospective decision study on an evaluation you have already completed to determine the quality of your team’s decision-making and the values the appear to have driven the decisions you made. Are you proud of those values?
Model a major decision your stakeholders are trying to make in terms of the utilities derived from your evaluation. Remember that ordinal utilities are sufficient for many decisions.